#!/usr/bin/python3 from matplotlib import colors import pandas as pd import numpy as np import os import matplotlib.pyplot as plt import cartopy.crs as ccrs import cartopy.feature as cfeature from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter import matplotlib.ticker as ticker from matplotlib.pyplot import MultipleLocator color_list = list(colors.XKCD_COLORS.items()) # 这个列表是为了循环颜色。说明白点就是,浮标的数量太多,我懒得一个一个定义颜色,所以直接获取包里面的颜色,使用十六进制来设置颜色,后面还会提到。
在画轨迹的时候还需要使用到Cartopy工具来绘制地图。接下来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
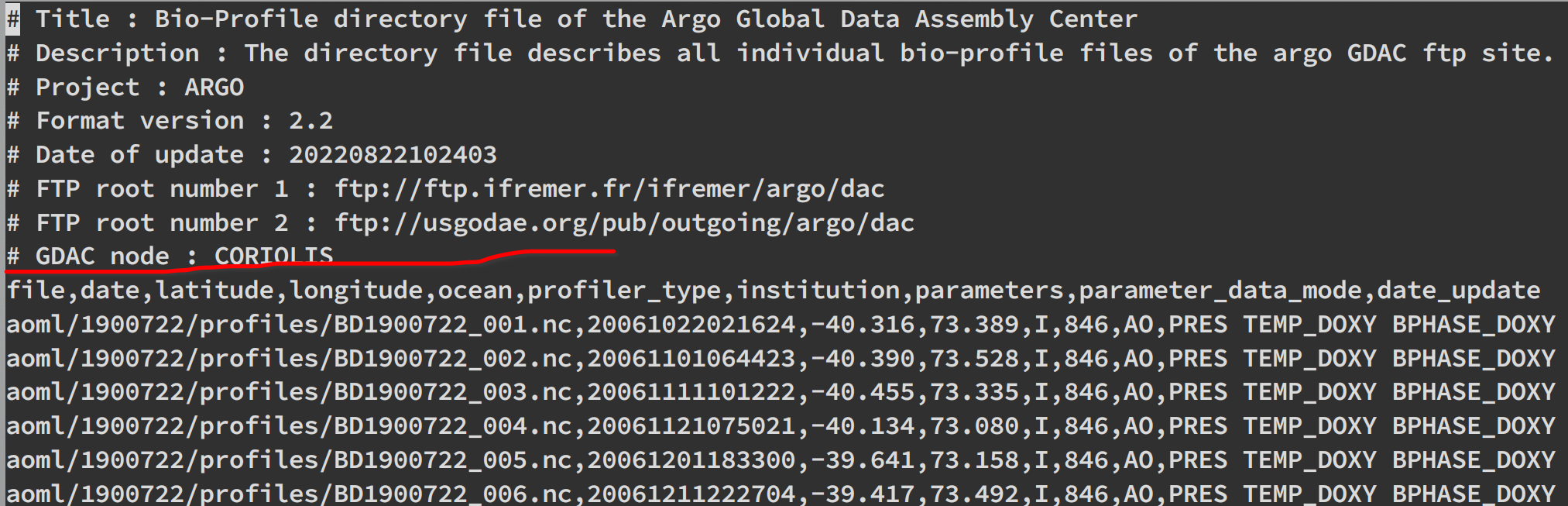
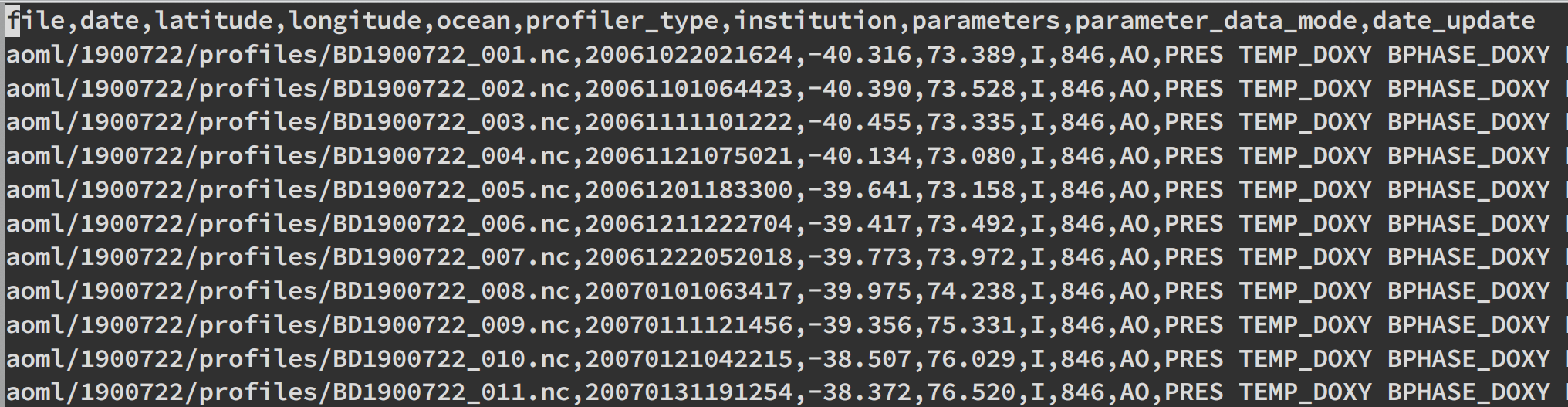
# out = pd.read_csv('argo_bio-profile_index.txt') # 读取原始的txt文件 # for i_file in range(len(out['file'])): # temp = out['file'][i_file].split('/') # ['aoml', '1900722', 'profiles', 'BD1900722_001.nc'] # if temp[0] != 'csio': # 这一步是为了筛选csio的产品,如上面文件名所示,产品有aoml等,这里我们只需要csio的产品,(老板要求的 # out = out.drop(labels=i_file) # 如果产品不是csio就把这一行删除 # out.to_csv('result.csv') # 存下来,以后直接读取这个处理好的文件,减少运算时间
# out = pd.read_csv('result.csv') # for i_file in range(len(out['file'])): # out['file'][i_file] = out['file'][i_file].split('/')[1] # 提取第一列的浮标号作为第一行的信息 # out.to_csv('final.csv') # 同样存下来
Comments